

include预处理指令
其实我们早就有接触文件包含这个指令了, 就是 #include,它可以将一个文件的全部内容拷贝另一个文件中。
使用语法:
第一种:#include <文件名>
直接到 C 语言库函数头文件所在的目录中寻找文件。
第二种:#include "文件名"
会先在源程序当前目录下寻找,若找不到,再到操作系统的 path 路径中查找,最后才到 C 语言库函数头文件所在目录中查找。
使用注意:
#include 指令允许嵌套包含,比如 a.h 包含 b.h,b.h 包含 c.h。但是不允许递归包含(循环包含),比如 a.h 包含 b.h,b.h 包含 a.h。
使用 #include 指令可能导致多次包含同一个头文件,降低编译效率,比如下面的情况:
在 one.h 中声明了一个 one() 函数,在 two.h 中声明了一个 two 函数,并且 two.h 中包含了 one.h。
假如我想在 main.c 中使用 one() 和 two() 两个函数,而且有时候我们并不一定知道 two.h 中包含了 one.h,所以可能会同时引入 one.h 和 two.h。
编译预处理之后 main.c 的代码是这样的:
void one();
void one();
void two();
int main () {
return 0;
}第1行是由 #include "one.h" 导致的,第2、3行是由 #include "two.h" 导致的(因为 two.h 里面包含了 one.h)。可以看出来,one() 函数被声明了2遍,根本就没有必要,这样会降低编译效率。
为了解决这种重复包含同一个头文件的问题,一般我们的头文件会使用条件编译:
one.h:
#ifndef _ONE_H_
#define _ONE_H_
void one();
#endiftwo.h:
#ifndef _TWO_H_
#define _TWO_H_
#include "one.h"
void two();
#endif以 one.h 为例:当我们第一次 #include "one.h" 时,因为没有定义 _ONE_H_,所以第1行条件成立,接着在第2行定义了 _ONE_H_ 这个宏,然后在3行声明 one() 函数,最后在4行结束条件编译。
当第二次 #include "one.h",因为之前已经定义过 _ONE_H_ 这个宏,所以第1行的条件不成立,直接跳到第4行的 #endif,结束条件编译。
就是这么简单的3句代码,防止了 one.h 的内容被重复包含。
多文件开发
大家都知道我们的 C 程序是由1个1个的函数组成的,当我们的程序很大的时候,将这些函数代码写在同1个文件之中是绝对不科学。函数太多,不方便管理,并且不利于团队开发。
我们的程序实际上都是分为1个1个的模块的,无论多大的程序都是由1个1个的小功能组成的。模块就是功能相同或者相似的一些函数。在实际开发中,不同的人负责开发不同的功能模块,要使用模块中的功能的话,直接调用就可以了。
如何写模块?
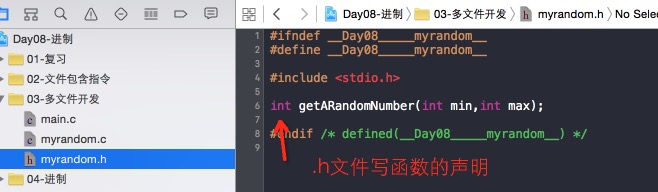
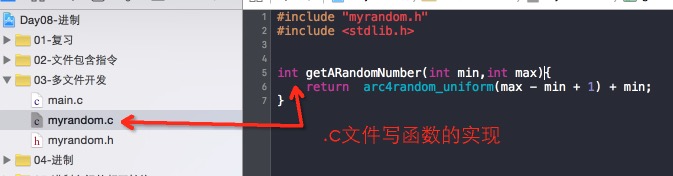
写模块的人,一般情况下要写两个文件。.c 源文件 .h 头文件。
.h 文件之中,写上函数的声明。
.c 文件之中,写上函数的实现。
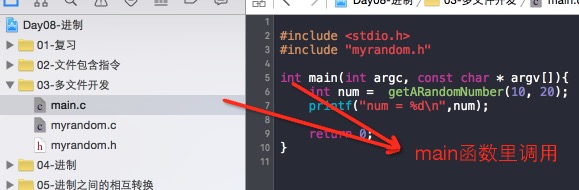
想要调用模块之中的函数,只需要包含这个模块的头文件就可以了。比如我们使用 printf 函数需要包含 stdio.h 头文件一样,只要包含了函数的声明,我们就能直接使用函数了。
例如:
我们还能给模块分组,例如:
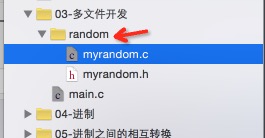
右键,选择 New Group 可以创建组,进行源文件分组管理。放在组里的源文件其实他的路径是不会改变的:
注意:New Group 只是创建的逻辑目录,如果想要实现真正分组,还得在文件系统目录建立真实的文件夹才行。
认识进制
什么是进制?
进制是记数的一种方式,侧重点在于记数的时候,是逢多少进一。比如我们日常生活中用的十进制,逢10进1。C 语言中也有进制,C 语言能识别的进制有二进制,十进制,八进制,十六进制。多少多少进制就是逢多少进1。
二进制:逢二进一,每1位用0和1表示。
在 C 语言的代码中,如果要写1个二进制的数,那么就必须要在这个二进制数的前面加 0b 前缀。
C 语言没有提供格式控制符来将1个整形变量中的数据以二进制的形式输出。
八进制:逢八进一,每1位 0、1、2、3、4、5、6、7中的任意1位来表示。
在 C 语言之中,如果要写1个八进制的数,那么就必须要在这个八进制的数的前面加1个前缀 0。
格式控制符 %o 会将整形变量中的数据以八进制的形式输出。
十进制:逢十进一,每1位 0 1 2 3 4 5 6 7 8 9 中的任意一位。
在 C 语言之中直接写1个整数,默认就是十进制。
格式控制符 %d 是将整形变量中的数据以十进制的形式输出。
十六进制:逢十六进以,每1位 0 1 2 3 4 5 6 7 8 9 a b c d e f 中的任意1位来表示。
如果我们要在 C 语言中写1个十六进制的数 那么就必须要在这个数的前面加1个前缀 0x。
格式控制符 %x 将整形变量中的数据以十六进制的形式输出。
进制直接的互相转换
我们先来引入一个概念,当然,C 语言中没有规定这些,是便于学习者进行按位运算而自己定义的概念。
数码:一个数的每一位数字,就叫做数码。
数位:数码在这个数中的位置,从右到左,从0开始增长。
基数:每一位数码最多可以由多少个数字来表示,多少进制就是多少基数。
位权 = 数码 * (基数的数位次方)
进制之间的转换:
十进制转二进制:除2取余,直到商为0,再余数倒序
十进制转八进制:除8取余,直到商为0,再余数倒序
十进制转十六进制:除16取余,直到商为0,再余数倒序
二进制转十进制:每一位的位权相加
八进制转十进制:每一位的位权相加
十六进制转十进制:每一位的位权相加
二进制转换八进制:3合1,低位到高位,每3位分成一组,高位不够补0,求出每一组的10进制,再相连
八进制转二进制:3拆1,将八进制的每1个数码,拆成1个三位的二进制,再将这些二进制连起来
二进制转十六进制:4合1,低位到高位,每四位分成1组,高位不够补0,求出每1组的10进制,再相连
十六进制转二进制:1拆4,将十六进制的每1个数码,拆成1个四位的二进制1再将这些二进制连起来
八进制转十六进制:八进制 -> 二进制 ->十六进制
打印二进制的函数:
//传入一个整数,打印他的二进制
void printBinary(int num) {
//定义一个临时变量temp,储存位移后的数据
int temp = 0;
//定义一个临时变量temp1,储存按位与后的二进制最低位数值
int temp1 = 0;
for (int i = 0; i < 32; i++) {
//先位移,截取数据
temp = num >> (31-i);
//再与1按位与,因为任何数与1与都能得到那个任何数的二进制的最低位
temp1 = temp & 1;
//取出一位打印一位
printf("%d",temp1);
}
printf("\n");
}原码,反码,补码
声明1个变量,其实就是在内存之中申请指定字节数(1字节 = 8位)的空间,用来存储数据。无论任何数据在内存之中都是以其二进制的形式存储的,并且是以这个数据的二进制的补码的形式存储的。那什么是补码呢?原码、反码、补码 都是二进制,只不过是二进制的不同的表现形式。
强调:所有的数据都是以其二进制的补码的形式存储在内存之中的。
原码:最高位用来表示符号位,0代表正,1代表负。其他叫数值位,数值位是这个数的绝对值的二进制位。
9的原码: 0 0000000 00000000 00000000 00001001
-3的原码:1 0000000 00000000 00000000 00000011反码:正数的反码就是其原码。负数的反码,是在其原码的基础之上,符号位不变,数值位取反。
9的原码: 0 0000000 00000000 00000000 00001001
9的反码: 0 0000000 00000000 00000000 00001001
-3的原码:1 0000000 00000000 00000000 00000011
-3的反码:1 1111111 11111111 11111111 11111100补码:正数的补码就是,其原码。负数的补码,是在其反码的基础之上加1。
9的原码: 0 0000000 00000000 00000000 00001001
9的反码: 0 0000000 00000000 00000000 00001001
9的补码: 0 0000000 00000000 00000000 00001001
-3的原码:1 0000000 00000000 00000000 00000011
-3的反码:1 1111111 11111111 11111111 11111100
-3的补码:1 1111111 11111111 11111111 11111101为什么要用补码来储存数据,因为计算机之中只有加法,没有减法。为了更低成本的计算出结果,所以使用补码来存储数据。如下例子:3 + (-2) = 1
原码计算:
0 0000000 00000000 00000000 00000011
1 0000000 00000000 00000000 00000010
------------------------------------
1 0000000 00000000 00000000 00000101 这个结果不对. 已经变成负数了.反码计算:
0 0000000 00000000 00000000 00000011
1 1111111 11111111 11111111 11111101
-------------------------------------
0 0000000 00000000 00000000 00000000 0 这也是错的.补码计算:
0 0000000 00000000 00000000 00000011
1 1111111 11111111 11111111 11111110
-------------------------------------
0 0000000 00000000 00000000 00000001 1 1结果是对.我们知道了原码、反码、补码的转换方法,那他们各自作用是什么?
原码:可以直观的反应出数据的大小。
反码:只是为了方便原码和反码的互相转换。
补码:将加减运算统一为加法运算。
位运算
什么叫做位运算?
1个二进制数的每1位来参与运算,参与位运算的前提,是这个数必须是二进制数。并且参与运算的二进制数据必须是补码的形式,并且算出来的结果也是补码。
按位与 &:
指的是两个数的二进制的补码,按位进行与运算。如果都为1结果就为1,否则就为0。
3 & 2
0 0000000 00000000 00000000 00000011
0 0000000 00000000 00000000 00000010
------------------------------------
0 0000000 00000000 00000000 00000010注意:任何数按位与1,结果是这个数的最低位
3 & 1
0 0000000 00000000 01001000 10010001
0 0000000 00000000 00000000 00000001
--------------------------------------
0 0000000 00000000 00000000 00000001偶数的最低位一定是0,奇数的最低位一定是1。
用1个数去按位与1,如果结果为0,那么这个数一定是1个偶数,如果结果为1,那么这个数一定是1个奇数。
#include <stdio.h>
int main() {
int num = 100;
//任意数按位与1,都能得到他的二进制位的最低位,如果最低位是1,则是奇数,是0则是偶数。
if (!(num & 1)) {
printf("偶数\n");
} else {
printf("奇数\n");
}
return 0;
}按位或 |:
参与按位或的二进制补码,只要有1位为1,那么结果就为1,只有都为0的时候才为0。
3 | 2
0 0000000 00000000 00000000 00000011
0 0000000 00000000 00000000 00000010
-------------------------------------
0 0000000 00000000 00000000 00000011按位取反 ~:
这是1个单目运算符,只需要1个数据参与,将1变0,0变1
~3
0 0000000 00000000 00000000 00000011
1 1111111 11111111 11111111 11111100 补码
1 1111111 11111111 11111111 11111011 反码
1 0000000 00000000 00000000 00000100 -4按位异或 ^
参与按位异或的二进制补码,比较对应的每一位,相同为0,不同为1。
3 ^ 5
0 0000000 000000000 00000000 00000011
0 0000000 000000000 00000000 00000101
----------------------------------------
0 0000000 000000000 00000000 00000110 +6实现交换两个变量的值:
#include <stdio.h>
int main() {
int a = 3, b = 2;
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("a = %d, b = %d \n", a, b);
return 0;
/*
分析
3 = 0 0000000 00000000 00000000 00000011
2 = 0 0000000 00000000 00000000 00000010
a = a ^ b
0 0000000 00000000 00000000 00000011
0 0000000 00000000 00000000 00000010 ^
a= 0 0000000 00000000 00000000 00000001 = 1
b = a ^ b
0 0000000 00000000 00000000 00000001
0 0000000 00000000 00000000 00000010 ^
b= 0 0000000 00000000 00000000 00000011 = 3
a = a ^ b
0 0000000 00000000 00000000 00000001
0 0000000 00000000 00000000 00000011 ^
a= 0 0000000 00000000 00000000 00000010 = 2
最终a = 2, b = 3, 成功交换了两个数的值
*/
}按位左移 <<:
1个二进制补码按位左移,就是将这个二进制位,向左移动指定的位数,溢出部分丢弃 低位补零。
3 << 2
0 0000000 00000000 00000000 00000011
0 00000 00000000 00000000 0000001100 12注意:
1个数按位左移,有可能改变其正负性。
1个数按位左移n位,相当于这个数乘以2的n次方。
16 << 3; 相当于16 2的3次方。就是16 8 = 128
按位右移 >>:
参与按位右移的二进制的补码,向右移动指定的位数,溢出部分补齐,高位补符号位。
3 >> 2
0 0000000 00000000 00000000 00000011
0 000000000 00000000 00000000 000000 0注意:
1一个数按位右移,不会改变1个数的正负性。
1个数按位右移n位,相当于这个数除以2的n次方。
变量存储原理
声明一个基本数据类型的变量,系统会自动在栈内存从高地址向低地址分配固定字节的内存空间,存储数据是按低位存储到低地址,高位存储到高地址的原则,并且存储在内存中的数据都是以二进制的补码形式存储。
比如声明一个 int 类型的变量并赋值10。
int num = 10;假如在栈内存中的内存地址是从0x000003 - 0x000000,那么存储数据如下所示:
0x000000 00001010
0x000001 00000000
0x000002 00000000
0x000003 00000000变量地址:并且这个 num 变量的地址是低地址,也就是0x000000是变量地址。
int类型的修饰符
我们声明1个 int 类型的变量,会在内存之中申请4个字节的空间,可以存储的数据-2147483647到+2147483648之间的整数。可是有的时候,数据要不了那么大,4个字节就显得很浪费。而有的时候,数据太大,4个字节又不够。这个时候,我们就可以使用 int 类型的修饰符来解决这个问题了。
int 类型的修饰符有 short、long、long long。他们可以限定 int 类型的变量在内存之中占据多少个字节。
short
被 short 修饰的 int 变量,在内存之中占据2个字节。在不考虑正负的情况可以表示65536个数。最高位表示符号位可以储存-32767到+32768之间的整数。我们可以使用 %hd 来输出 short int 变量的值,如果要声明 short int 变量的话. 可以省略 int。比如:short num = 12;
long
被 long 修饰的 int 变量,在内存之中占据8个字节(64位编辑器),使用 %ld,输出 long int 变量的值。并且如果要声明1个 long int 变量,可以省略 int。比如:long num = 100;
long long
被 long long 修饰的 int 变量无论是多少位的系统都占据8个字节,使用 %lld 来输出 long long int 变量的值。并且也可以省略 int 。比如:long long num = 100;
unsigned
我们声明1个 int 类型的变量,占据4个字节,最高位用来表示符号位。但是我们可以使用1个关键字,让这个变量的最高位不表示符号位,全部位数都用来表示数据。这样最小值就只能存储0,但是最大值可以翻番。
signed
要求变量的最高位用来表示符号位,默认就是这样的。所以这个关键词一般没啥用。